SURVEY THE MILLENNIUM BUG
The art of bug-hunting
Search archive
|
Find them, zap them, test—and keep your fingers crossed |
|||
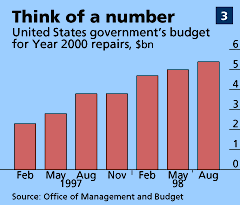
These days, IT departments curse people like young Varian. Many, especially in banks and government departments, are aghast at the sheer volume of ancient code. “Companies always have an order of magnitude more than they think,” say Gary Miles, of PA Consulting Group. They may also discover some long-lost systems. “In one bank, we found two IT departments that the management didn’t know about,” he says. Most organisations seem to find that millennium work costs more than expected (see chart 3 for the American government’s experience). Not only is the task huge, it is also deadly dull (“like sorting out your sock drawer,” says one veteran).
 |
|
But locating bugs is only the first of the three main stages of the process, to be followed by treating them in one of several ways, and then by testing to try to ensure that the problem is solved. Moreover, locating rogue dates on computers is often easier than finding all the bits of equipment that may contain date-sensitive embedded systems. One of the best guides to that problem, by Britain’s Institution of Electrical Engineers, laments:
|
The general problems are that: a) no one knows how many embedded systems there are and where they are (except that they are “everywhere”), and they are not always easy to detect; b) no one knows which embedded systems have devices in them which depend on date information; c) there are very many different ways in which the problem might show up, and new aspects continue to be found. |
|
Companies know even less about their embedded systems than about their software. There is no systematic catalogue, nor any general standard: as Harris Miller, president of the Information Technology Association of America, the industry’s main trade group, points out, “You don’t buy a chip, you buy a medical device, and the maker of the device may have bought the chip as part of a component.” Many of the companies that used to make micro-processing chips have, like those early programmers, vanished from the scene.
Commonwealth Bank in Australia tackled the task by tracking down 25,000 devices containing embedded chips and subjecting them to risk analysis. “We think 3-6% may be affected,” says Ken Pritchard, who directs the Year 2000 programme. “Most are in air conditioning, security and power. We’ve gone back to the vendors where we can, but we can’t test them ourselves. So we’re asking whether they have a significant effect, and if so, can we live with it? If not, we replace them.”
Some of those who hunt for troublesome chips say reassuringly that the problem is quite small. Dean Kothmann, general partner at Black & Veatch, a consultancy that specialises in chip searches, estimates that fewer than 10% of embedded systems have a date problem, and fewer than 10% of those have a “hard” failure, which shuts them down, rather than a “soft” failure, which merely generates screwball numbers.
But that 1%, if missed, can cause a disproportionate amount of trouble. Charles Siebenthal, a senior engineer at the Electric Power Research Institute (EPRI) in California, describes a test in an American nuclear-power station: the device that controlled the depth of the fuel rod in the core began to oscillate because the air-conditioning system in the control room failed and the temperature rose. Nobody had bothered to check that.
The next step is to ask the supplier of the original software or chip whether the product is millennium-compliant. Some suppliers provide Year 2000 information via elaborate web sites: indeed, the Internet has emerged as a global source of such information. Some suppliers contact customers without waiting for a call. IBM, for instance, has tried to write to all large purchasers of its equipment over the past decade to tell them whether the product is fit for the millennium. But many suppliers either do not know—or do not answer.
Once the troublesome components have been identified, companies have two main options: repair or replace. For early birds, replacement provided a chance to introduce more coherent software systems, creating a boom for companies such as SAP which sell them. However, such re-engineering generally needs a good two years, which means that organisations starting only now will have little option but to repair.
Replacing parts in embedded systems is quicker. No need to write new software; simply rip out one component, stick in another and hope the rest of the system still works. Often this is the only option. “In many instances,” says James Eddison, a Year 2000 project manager at Unilever, “it is almost impossible to test embedded chips because they are in ‘black box’ situations. You choose between an assurance from the supplier or replacement.”
With some packaged software, the answer is a “patch”: a small addition to the original code, written by the supplier, that bypasses or corrects the problem. Most PC operating systems and applications at risk are being corrected that way. But with the software code that companies have written for customised applications, the answer is often to use a search program to hunt for some 20 or so words commonly used in programming to denote time, and add the two extra digits. This offers a permanent solution, but it is time-consuming and expensive—and often there is not enough space to squeeze in the extra bytes of code. A stop-gap alternative is “windowing”: writing software that instructs a computer to treat every date before a certain year as belonging to the next century. Such a solution works for relatively short-lived items such as mortgages but not, in an age with more and more centenarians, for medical records. A third short-term option is to add a program to convince the computer that the year after 1999 is 1972, which began on the same day of the week as 2000 will, and was also a leap year.
Once companies start dealing with their big problems, they begin to notice lots of smaller problems, which may be less complicated in IT terms but much harder for managers to deal with. These spring from the fashion for distributed systems—networks of PCs in individual departments. EDS, an outsourcer, talks gloomily of one company with 50 types of desktop computers, and another with 20,000 individual desktop PCs, only half of them millennium-ready. Where the users have written their own applications, “they have to bring us out to sit with them” and unravel the mess.
The most time-consuming part of the task turns out to be testing. This is much harder to farm out than correction, because a test needs to ensure that all of a company’s systems will work together, not just one in isolation. Testing software requires extra capacity, or needs to be carried out at a weekend.
“Testing is hell,” says J.P. Morgan’s Mr Miller. It generally seems to take about 60% of the time needed to make a company millennium-ready. Alter one line of code, or replace one device with another, and the system may no longer work.
That, moreover, is merely in one plant. Once a company’s systems are individually compliant, the next stage is to test whether they work with each other. That may be harder if different departments have been allowed to adopt different solutions. The companies that are farthest ahead, such as large American financial institutions, are now moving on to the most complex stage of all: testing whether their millennium-compliant systems will still work with those of their business partners.
Try triage
Even if all testing is successfully completed, a company’s troubles are not over. What happens if new software is introduced before the big date? Many firms are reaching the same conclusion as Visa, which is now far enough ahead to have reduced the staff of programmers tackling the Year 2000 from 25 to three. “We’re freezing changes in the existing system after March,” says Ray Barnes, the group’s executive vice-president. “In September next year we will skip the roll-out of new products that we usually make twice a year. We’re being ultra-conservative.”
One of the main lessons from bug-hunting so far is the need for “triage”: setting priorities and determining which systems are “mission-critical” (lots of battlefield jargon here). Many organisations that began work later have realised that they have no hope of being entirely compliant in time. Instead, they need to be “millennium-ready”. That means identifying those systems that matter most to their business, fixing those that can be fixed and drawing up contingency plans to cope with the rest. Randy Bowden, who handles the Year 2000 for Unisys in Australia (one of the countries farthest along the road), argues that triage and contingency planning will become the two main themes of millennium work as the deadline approaches.
In addition, managers will increasingly find that their navigation of the millennium depends on whether their suppliers and distributors have dealt with their systems in turn. If the power is down, the taps run dry and the bank is shut, all that testing will not keep the business going.